
序
在日常工作或者面试的时候,我们会经常被问到或者说需要知道。当我们在浏览器中输入一个网址的时候,后面发生了 什么?
抓包分析
首先我们用浏览器访问127.0.0.1:8000,然后用Wireshark抓包查看整个过程。
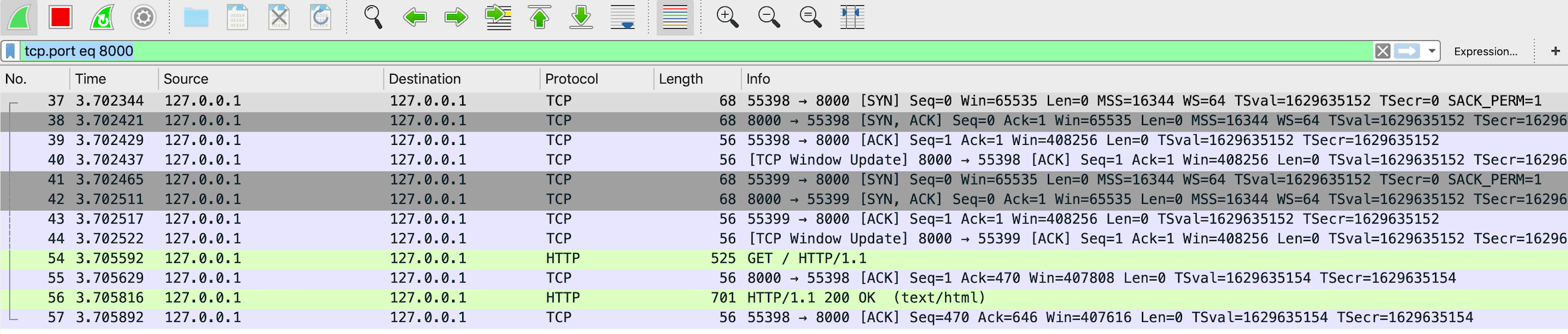
我们可以看到浏览器用55938这个端口和服务端的8000端口,先是通过37、38、39这三个序号,完成tcp/ip三次握手,建立连接。
然后在序号54,发送了一个GET请求。55、56则是服务器响应浏览器。57是浏览器向服务器发送ack包,表示收到。
如果没有其他操作,之后就是四次挥手。值得注意的是,四次挥手在上图抓包并没有体现出来,这是因为 HTTP/1.1 长连接特性,默认不会立即关闭连接。
至此,整个“键入网址再按下回车”的全过程就结束了。
抓包结论
知道了整个抓包过程以后,我们能得到什么结论呢?
从上面我们可以看到的是:
1、首先浏览器需要和服务器建立连接。
2、建立连接后浏览器发送http请求。
3、服务器接收到请求后响应请求。
4、浏览器告诉服务器接收到响应了。
5、最后断开连接。
真实的网络世界
从抓包结论第一点我们可以知道,浏览器需要先和服务器建立连接。但是真实的网络世界,我们往往不知道服务器的ip。
比如:www.baidu.com。
此时我们需要先获取到服务器所对应的ip。这也就是为什么说HTTP协议是基于底层的TCP/IP协议的。
域名解析
通过域名来获取服务器IP,这就是DNS域名解析了。
通常我们输入一个网址后,我们首先看浏览器是否有缓存,然后看操作系统是否有缓存,再看本地hosts文件(本地DNS)是否有相应配置。
如果都没有,就要从根DNS、顶级DNS、权威DNS,层层解析,去获取服务器IP。
除了DNS解析之外,这个过程还有一个重要角色:CDN。它会在DNS解析过程中”插上一脚”。DNS解析可能会给出CDN服务器的
IP地址。这样你拿到的就会是CDN服务器而不是目标网站的实际地址。
因为CDN会缓存网站的大部分资源,比如图片、CS样式,所以有的HTTP请求就不需要再发到服务器,CDN就可以直接响应你的请求,把数据发给你。
但是由PHP、JAVA等等后台服务动态生成的页面属于”动态资源”,CDN无法缓存,只能从目标服务器上获取。这就需要HTTP请求经过漫长的”跋山涉水”, 经过无数路由器、网关、代理,最后到达目的地。
到达目标网站
目标网站对外是一个ip,但是为了扛住高并发等问题,对内也是一套复杂的架构。
通常在入口是负载均衡设备,例如:四层的LVS或者是七层的Nginx。后面是许多的服务器,构成一个强而稳定的服务器集群。
负载均衡设备会先访问系统里的缓存服务器,通常有memory级缓存Redis和disk级缓存Varnish,它们的作用与CDN类似,
不过是工作在内部网络里,把最频繁访问的数据缓存一段时间,减轻后端应用服务器的压力。
如果缓存服务器里也没有,那么负载均衡设备就要把请求转发给应用服务器了。这里就是各种开发框架和语言大显神通的地方了。例如PHP、golang、java等。
它们又会再访问后面的MySQL、PostgreSQL、MongoDB等数据库服务,实现用户登录、商品查询、购物下单、扣款支付等业务操作,
然后把执行的结果返回给负载均衡设备,同时也可能给缓存服务器里也放一份。
最后网站的响应数据回到了浏览器,它可能是HTML、JSON、图片或者其他格式的数据,需要由浏览器解析处理才能显示出来,
如果数据里面还有超链接,指向别的资源,那么就又要重走一遍整个流程,直到所有的资源都下载完。
总结
当我们在浏览器输入一个网址再按下回车键时,整个请求-响应的全过程:
1、HTTP协议基于底层的TCP/IP协议,所以必须要用IP地址建立连接;
2、如果不知道IP地址,就要用DNS协议去解析得到IP地址,否则就会连接失败;
3、请求方与应答方通过三次握手建立连接;
4、建立TCP连接后会顺序收发数据,请求方和应答方都必须依据HTTP规范构建和解析报文;
5、为了减少响应时间,整个过程中的每一个环节都会有缓存,能够实现“短路”操作;
6、虽然现实中的HTTP传输过程非常复杂,但理论上仍然可以简化成"两点"模型。